

Over 80 percent of digital documents lack proper metadata, making valuable information difficult to access or manage. As organizations grow and data piles up, the challenge of locating, organizing, and protecting digital assets only increases. Understanding how metadata extraction works can turn cluttered files into structured resources, offering businesses a way to boost efficiency, ensure compliance, and improve document searches with confidence.
Table of Contents
- Defining Metadata Extraction And Its Role
- Key Metadata Types And Data Sources
- How Metadata Extraction Works In Practice
- Business Applications In Pdf Workflows
- Challenges, Risks, And Best Practices
Key Takeaways
| Point | Details |
|---|---|
| Role of Metadata Extraction | It transforms unstructured digital content into organized, searchable information, improving document management workflows and insights. |
| Types of Metadata | Key categories include descriptive, structural, administrative, technical, and legal metadata, providing comprehensive context for digital assets. |
| Business Applications | In PDF workflows, its use enhances compliance management, knowledge repositories, and regulatory reporting, streamlining document processing. |
| Challenges and Best Practices | Organizations face data inconsistency and privacy concerns; implementing robust validation and adaptive technologies is crucial for effective extraction. |
Defining Metadata Extraction and Its Role
Metadata extraction is the systematic process of identifying, capturing, and retrieving descriptive information about digital assets, transforming raw data into meaningful insights. As defined by the datascience.nih.gov Workbook of Metadata Fundamentals, metadata serves as a critical framework for understanding the context, structure, and characteristics of digital information.
At its core, metadata extraction involves automatically uncovering semantic details embedded within various digital file formats. According to en.wikipedia.org, this process utilizes specialized automated tools designed to discover and map data elements across complex systems. These tools help organizations transform unstructured information into structured, searchable, and manageable digital assets.
The primary functions of metadata extraction include:
- Providing comprehensive context for digital documents
- Enabling efficient search and retrieval mechanisms
- Supporting compliance and governance requirements
- Facilitating seamless data integration across platforms
- Enhancing overall document management workflows
By systematically capturing key attributes such as creation date, author information, file type, and content description, metadata extraction empowers businesses to transform raw digital files into intelligent, navigable resources. Organizations can leverage these extracted metadata insights to optimize document processes, improve information accessibility, and drive more informed decision making.
Key Metadata Types and Data Sources
Metadata types encompass a diverse range of descriptive information that provide context and structure to digital assets. According to en.wikipedia.org, the International Press Telecommunications Council has developed comprehensive metadata formats that span various digital media types, establishing critical standards for information classification and interchange.
These metadata categories typically include:
- Descriptive Metadata: Information about content characteristics
- Structural Metadata: Details about file organization and relationships
- Administrative Metadata: Management and preservation information
- Technical Metadata: System and format-specific technical specifications
- Legal Metadata: Copyright, usage rights, and permissions
In specialized domains like machine learning, metadata formats are becoming increasingly sophisticated. en.wikipedia.org highlights emerging standards like the Croissant metadata format, which supports advanced dataset sharing and standardization across complex digital repositories. These evolving formats demonstrate how metadata extraction is moving beyond simple file description toward creating intelligent, interconnected data ecosystems.
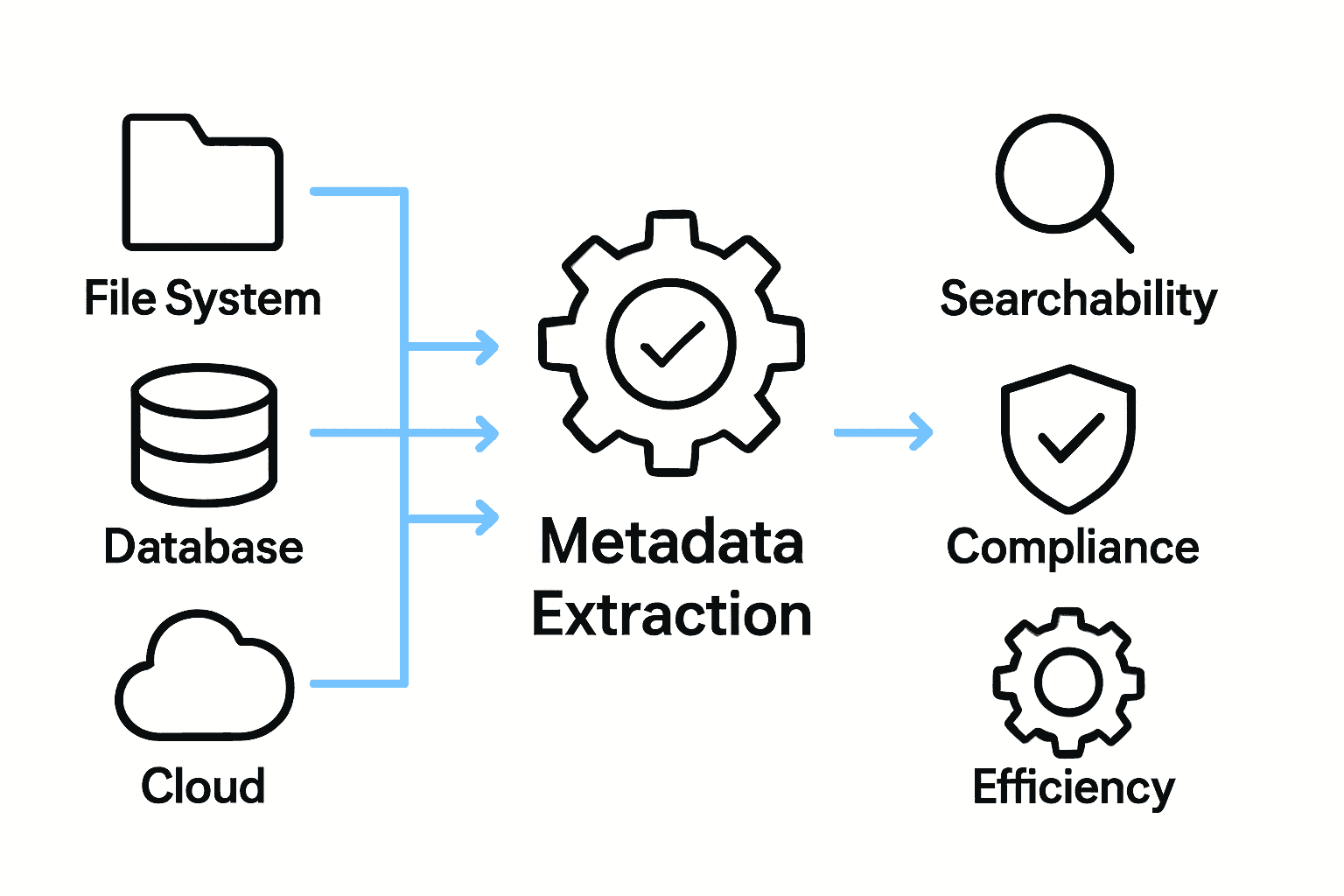
The primary data sources for metadata extraction include file systems, databases, document repositories, cloud storage platforms, and specialized software applications. Each source offers unique metadata attributes, ranging from basic file properties like creation date and size to more complex information such as content analysis, user permissions, and version history. By aggregating metadata from multiple sources, organizations can develop comprehensive digital asset management strategies that enhance searchability, compliance, and operational efficiency.

How Metadata Extraction Works in Practice
Metadata extraction is a sophisticated process that transforms unstructured digital content into organized, searchable information. According to research from arxiv.org, advanced techniques like the MeXtract model demonstrate how specialized language models can be fine-tuned to extract precise metadata across diverse document types, showcasing the remarkable precision of modern extraction technologies.
The practical workflow of metadata extraction typically involves several critical stages:
- Document Ingestion: Collecting digital files from various sources
- Parsing: Breaking down document structures and identifying potential metadata fields
- Recognition: Using machine learning algorithms to detect and classify metadata elements
- Validation: Cross-referencing extracted metadata against predefined schemas
- Normalization: Standardizing metadata formats for consistent interpretation
Cutting-edge research, such as the study published on arxiv.org, is exploring innovative approaches that integrate large language models with external vector databases. These advanced techniques enable more nuanced metadata-based data discovery, allowing organizations to develop increasingly intelligent systems that can semantically analyze and connect diverse datasets.
At its core, metadata extraction transforms raw digital assets into intelligent, structured resources.
By systematically capturing and organizing descriptive information, businesses can unlock powerful insights, improve searchability, and create more efficient document management workflows. The technology continues to evolve, promising even more sophisticated methods of understanding and leveraging digital information in the coming years.
Business Applications in PDF Workflows
PDF workflow automation has revolutionized how organizations manage, process, and extract value from digital documents. Research from ceur-ws.org highlights the critical importance of metadata extraction in making document repositories more accessible and intelligently organized, particularly for scholarly and business contexts.
Specific business applications of metadata extraction in PDF workflows include:
- Compliance Management: Automatically tracking document versions, author information, and access permissions
- Knowledge Management: Creating searchable repositories of organizational documents
- Legal Documentation: Ensuring precise tracking of contract metadata, signatures, and critical timestamps
- Research and Development: Organizing scientific publications and technical reports with comprehensive metadata tags
- Regulatory Reporting: Automatically generating standardized metadata for audit and reporting purposes
According to sloap.org, machine learning techniques are increasingly sophisticated in automating metadata extraction, enabling businesses to transform complex PDF documents into structured, easily navigable information assets. These advanced techniques can now recognize and categorize metadata elements with remarkable accuracy, reducing manual processing time and minimizing human error.
By Master PDF Workflow Automation for Your Business, organizations can leverage metadata extraction to create more intelligent, efficient document management systems. The technology not only streamlines information retrieval but also provides deeper insights into document content, usage patterns, and organizational knowledge repositories.
Challenges, Risks, and Best Practices
Metadata extraction presents complex technical and strategic challenges that organizations must carefully navigate. According to research from arxiv.org, ensuring long-term digital preservation requires robust metadata strategies that go beyond simple data collection, emphasizing the need for comprehensive and adaptable metadata frameworks.
Key challenges in metadata extraction include:
- Data Inconsistency: Variations in document formats and metadata structures
- Privacy Concerns: Protecting sensitive information during extraction
- Computational Complexity: Managing large-scale metadata processing
- Quality Control: Ensuring accuracy and completeness of extracted metadata
- Technological Obsolescence: Keeping extraction methods current with evolving file formats
From a legal perspective, irshadjournals.com highlights the critical importance of precise metadata extraction, particularly for evidentiary purposes. This underscores the need for rigorous validation processes and transparent extraction methodologies that can withstand legal and forensic scrutiny.
Best practices for effective metadata extraction involve implementing comprehensive validation protocols, investing in adaptive machine learning technologies, maintaining strict data privacy standards, and developing flexible extraction frameworks that can accommodate diverse document types. By anticipating potential challenges and proactively addressing them, organizations can transform metadata extraction from a potential risk into a powerful strategic asset.
Unlock the Full Potential of Metadata Extraction with Mapsoft Solutions
Metadata extraction is critical for transforming chaotic digital documents into organized, searchable assets. If you face challenges like inconsistent data formats, complex PDF workflows, or accurate metadata validation, you are not alone. The article clearly highlights how extracting, validating, and normalizing metadata is essential for compliance, automation, and improved document management.
At Mapsoft.com, we specialize in Adobe PDF technologies that directly address these pain points. Our PDF Hub platform empowers businesses to automate metadata extraction and management within large-scale PDF workflows. From editing metadata and securing documents to creating batch processing automation, Mapsoft provides practical tools to streamline your workflow and reduce costly manual errors.
Are you ready to take control of your digital assets and elevate your metadata strategy?
Explore Mapsoft.com for cutting-edge PDF and Adobe Acrobat® solutions designed to turn metadata extraction challenges into productivity breakthroughs. Start your journey toward smarter document management today.
Frequently Asked Questions
What is metadata extraction?
Metadata extraction is the process of identifying, capturing, and retrieving descriptive information about digital assets, transforming raw data into meaningful insights to enhance organization and accessibility.
What are the primary functions of metadata extraction?
The primary functions of metadata extraction include providing context for digital documents, enabling efficient search and retrieval, supporting compliance and governance, facilitating data integration, and enhancing document management workflows.
What types of metadata are commonly extracted?
Common types of metadata include descriptive metadata (content characteristics), structural metadata (file organization), administrative metadata (management information), technical metadata (system specifications), and legal metadata (copyright and usage information).
What challenges are associated with metadata extraction?
Challenges in metadata extraction include data inconsistency due to varied formats, privacy concerns regarding sensitive information, computational complexity in processing large data sets, quality control for accuracy, and technological obsolescence of extraction methods.

